Oracle has recently announced the release of a new version (4.1.0) of its Big Data Lite VM. Compared to the previous release (4.0.1), we now have more recent versions of Oracle Enterprise Linux (6.5), Oracle NoSQL database (3.2.5), Cloudera distribution of Apache Hadoop (CDH 5.3.0) and Cloudera Manager (5.3.0). The new version of CDH, by itself, also brings forward several upgrades, the most interesting perhaps being Apache Spark 1.2.0.
We got the new VM for a test drive, allocating to it six (6) processor cores and 24 GB of memory, and we found several issues. In this post we concentrate on Hadoop services configuration via the Cloudera Manager. In a follow up post, we will describe issues and solutions regarding Oracle R Enterprise.
Below are our first findings, and the solutions we applied.
Setting up & configuration
Following the provided instructions, we first switched off all Hadoop-related services using the manual configuration utility before enabling Cloudera Manager (CM). Trying to connect to the CM interface following the provided link at the ‘Getting Started’ document fails, as the link actually points to http://localhost:7001/movieplex/index.jsp, i.e. the movieplex demo, and not to http://localhost:7180 as the text indicates. To start the CM interface, we have to either type the address manually, or select “Cloudera Manager” from the browser’s bookmarks toolbar. After launching the CM interface, the services summary is shown in Fig. 1 below.
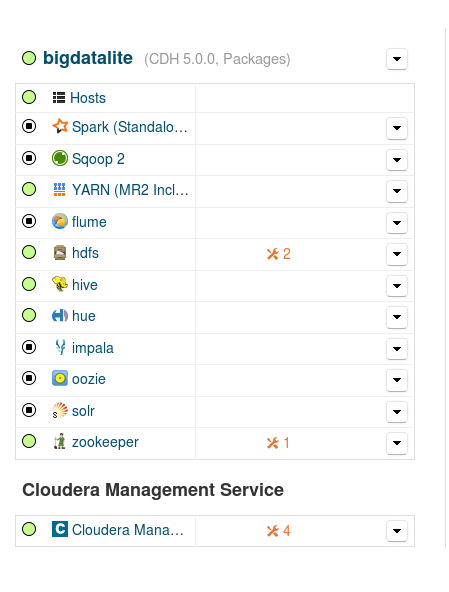
Fig. 1
The orange indication next to the Zookeeper service is a configuration issue, as we have only one server running the service, while Cloudera suggests at least three (3). We cannot remedy it in our case, as we in fact have a single-node cluster; the same issue pops up also for the HDFS service. We proceed to address the rest of the configuration issues in HDFS and the Cloudera Management Service, having to do with Java heap space and maximum non-Java memory of some nodes and services (clicking on the orange indications leads to the appropriate configuration pages – we restored the default recommended values).
The other issue that caught our attention is the indication for “CDH 5.0.0, Packages” in our node (bigdatalite, top of Fig. 1). Clicking the node pull-down menu and selecting “Configure CDH Version”, we get the message shown below:
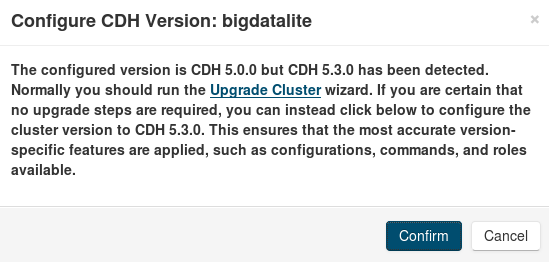
Fig. 2
Since we know that we have CDH 5.3.0 actually installed, we have no reason to upgrade the cluster; so, we select “Confirm”, and we proceed to restart our bigdatalite cluster.
Restarting the cluster does not merely restart the active services (i.e. services indicated green in Fig. 1 above); instead, it stops all running services and subsequently starts all the services present (installed) in the cluster. Hence, while the restart command attempts to start the Sqoop service, we get a failure message:
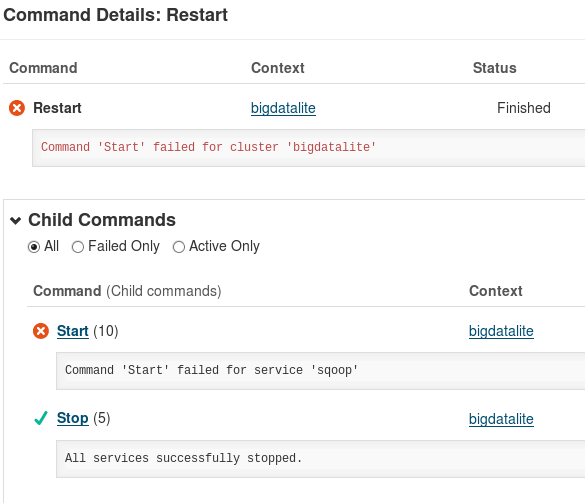
Fig. 3: Sqoop fails to start
Our services summary now looks like shown in Fig. 4 below (Hue service is not running, since the start command for the node was aborted after Sqoop failed to start, and Hue is supposed to start after Sqoop):
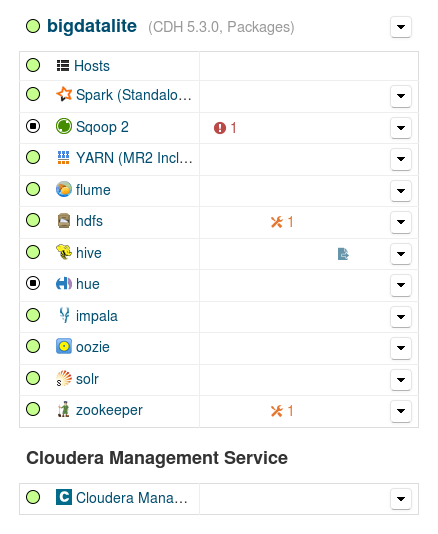
Fig. 4
Before dealing with the Sqoop failure, we notice the blue icon next to the Hive service; hovering the mouse over it, we get a warning for stale configuration and a recommendation for a Deploy Client Configuration wizard invoke and restarting again the cluster. We proceed to perform both (the Deploy Client Configuration command is available from the bigdatalite cluster pull-down menu). We get again the above error message for Sqoop (Fig. 3) and, after switching on also the Hue service, the picture is as shown in Fig. 5 below:
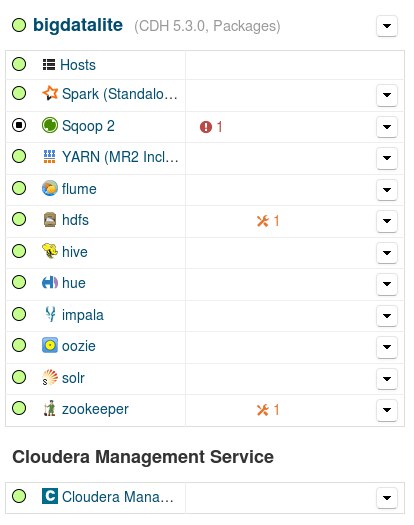
Fig. 5
Apart from the Sqoop health issue indicated, the rest of the services summary in Fig. 5 looks OK: we have now correctly configured the cluster with the CDH 5.3.0 distribution and all the other services are up and running; the configuration warnings for HDFS and Zookeeper routinely ask for 2 more server roles for the respective services, which is neither applicable nor critical in our situation. We proceed now to examine the Sqoop failure.
Sqoop issue
First, let us stress that the Sqoop failure described above has nothing to do with the CDH configuration update procedure, since it occurs even if we simply try to start the service before the configuration update.
Digging into Sqoop log files, we locate the following error message:
Server startup failure org.apache.sqoop.common.SqoopException: REPO_0002:Repository structures are not in suitable state, might require upgrade
It turns out that we have to upgrade Sqoop as follows:
- Click on Sqoop 2 in the services summary table
- From the Actions pull-down menu of the Sqoop 2 service (top right of the page, see Fig. 6 below), select “Upgrade Sqoop”
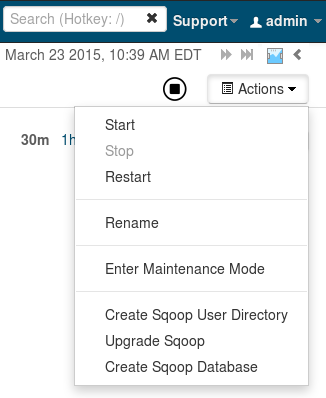
Fig. 6
- Go back to the Cloudera Manager home page, and start the Sqoop 2 service from its pull-down menu.
Sqoop now starts without any issue, and the services summary looks like that:
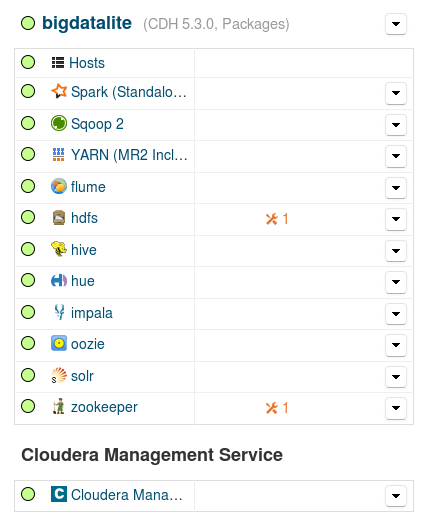
Fig. 7
Flume issue
On the surface, everything now looks smooth. Unfortunately, this is not exactly the case. The easiest way to confirm this is to try to restart the Cloudera Management service. The service does restart, but with a critical health issue:
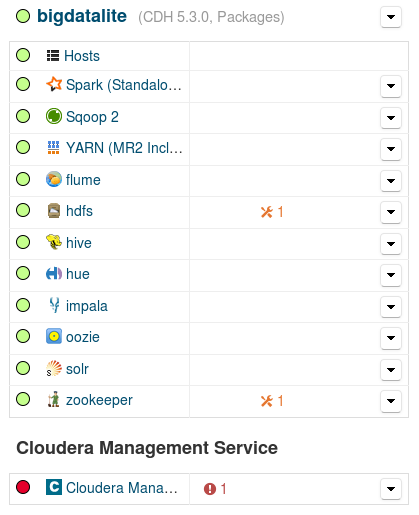
Fig. 8: Services summary after restarting the Cloudera Management Service
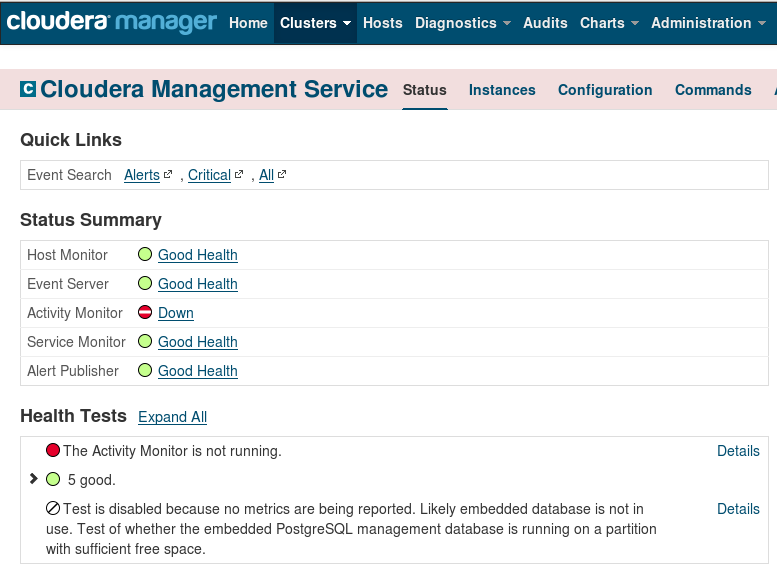
Fig. 9
Again, digging into CM Activity Monitor log files, we locate the following error:
Failed to start Firehose com.cloudera.enterprise.EnterpriseServiceException: java.net.BindException: Address already in use
following the warning
failed SelectChannelConnector@bigdatalite.localdomain:9999: java.net.BindException: Address already in use
What’s happening is that the Activity Monitor tries to connect to port 9999, but finds it in use, and fails. We can confirm that the port is already in use by running netstat in a terminal shell, with superuser privileges:
[oracle@bigdatalite ~]$ su [root@bigdatalite oracle]# netstat -tlpn | grep 9999 tcp 0 0 127.0.0.1:9999 0.0.0.0:* LISTEN 29679/java
The problem is due to the Flume default agent; to confirm this, we select Clusters -> Flume from the CM top menu, and from the resulting Flume menu Configuration -> Agent Default Group:
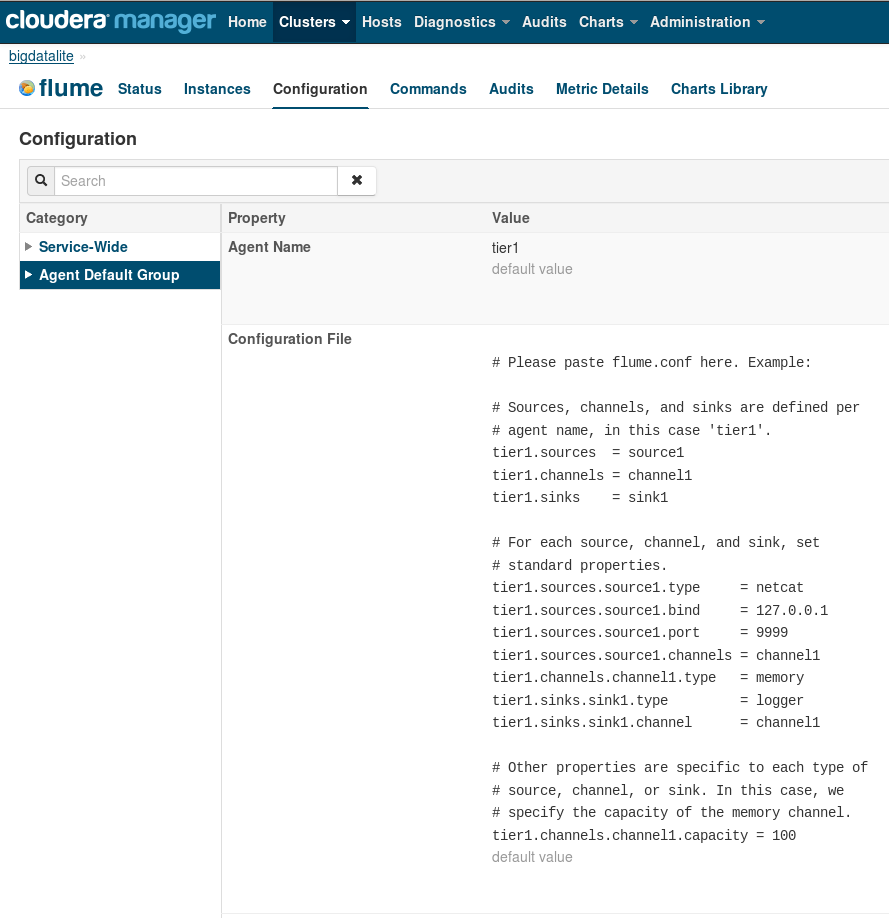
Fig. 10: Flume default agent configuration file
In the Configuration File, we can see that port 9999 is used by the Flume default agent (tier1).
Before remedying this, we have to notice that even before restarting the Cloudera Management service (i.e. with the situation as depicted in Fig. 7 above), there still exists an underlying problem, despite the fact that it is not visible from the services summary (“green” status of Flume in Fig. 7): the Flume default agent tries by its turn to connect to port 9999, finds it in use (by the CM Activity Monitor), throws an error, and repeats the attempt every 3 seconds, as shown in the excerpt below from the Flume log:
12:08:03.584 PM INFO org.apache.flume.source.NetcatSource Source starting
12:08:03.584 PM ERROR org.apache.flume.source.NetcatSource Unable to bind to socket. Exception follows.
java.net.BindException: Address already in use
12:08:06.586 PM INFO org.apache.flume.source.NetcatSource Source starting
12:08:06.586 PM ERROR org.apache.flume.source.NetcatSource Unable to bind to socket. Exception follows.
java.net.BindException: Address already in use
By manually setting the Flume default agent port to 9987 in the Configuration File (Fig. 10), we avoid the conflict between Flume and Cloudera Management services; the situation now looks again as in Fig. 7 above, and furthermore Flume is not logging errors. Restarting the Cloudera Management service now works OK, too.
Wrap-up
Summarizing, here are the necessary steps that must be taken, in order to end up with a smoothly functioning setup of Cloudera Manager and Hadoop services in Oracle Big Data Lite VM 4.1.0 (some cluster restarts between steps may be required – you will be prompted):
- Configure the correct CDH version (CM Home -> bigdatalite -> Configure CDH Version)
- Deploy this “new” client configuration (CM Home -> bigdatalite -> Deploy Client Configuration)
- Restore the default recommended values regarding Java heap space and maximum non-Java memory for the HDFS & Cloudera Management services (clicking on the orange warning icons in the services summary will lead you to the appropriate CM configuration pages).
- Upgrade Sqoop (CM Home -> Sqoop 2 -> Actions -> Upgrade Sqoop)
- Manually change the port for the default Flume agent to a suggested value of 9987 (CM Home -> Flume – > Configuration -> Agent Default Group -> Configuration File -> tier1.sources.source1.port
You should now have a functioning CM service. In our next post, we will look at some issues with Oracle R Enterprise – stay tuned!

- Streaming data from Raspberry Pi to Oracle NoSQL via Node-RED - February 13, 2017
- Dynamically switch Keras backend in Jupyter notebooks - January 10, 2017
- sparklyr: a test drive on YARN - November 7, 2016
Christos, this was a very helpful post for me. I found the same issues with the newer VM version (4.2) too. In addition there was a (new) error when I was trying to upgrade sqoop2. I could resolve this by deploying derby.jar and derbyclient.jar contained in db-derby-10.11.1.1-bin.zip from Apache Derby to /var/lib/sqoop2/. Important: This did only fix the upgrade bug and you have to remove this .jars before trying to restart sqoop2.
Thanks for this Eric. Didn’t find the time so far to look at VM 4.2, but I hope to do so soon.