I ran into an issue recently, while trying to bulk load some data to HBase in Oracle Big Data Appliance. Following is a reproducible description and solution using the current version of Oracle Big Data Lite VM (4.4.0).
Enabling HBase in Oracle Big Data Lite VM
(Feel free to skip this section if you do not use Oracle Big Data Lite VM)
If you use Oracle Big Data Lite VM as your development environment with Cloudera Manager enabled, you might have noticed that, rather surprisingly, HBase is not included in the Cloudera-managed Hadoop services:
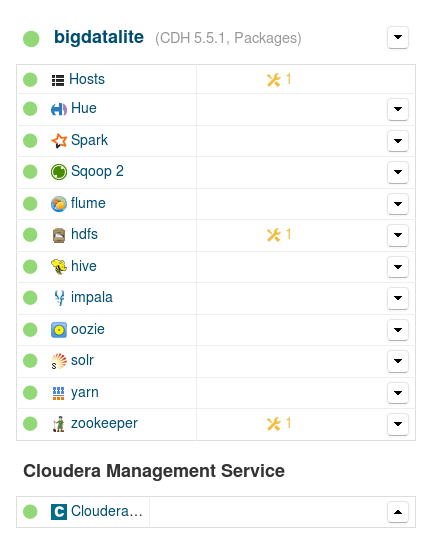
Cloudera-managed services in Oracle Big Data Lite VM – notice that HBase is not included
We can still start HBase from the shell, but nevertheless we get an error if we try to run any command:
[oracle@bigdatalite ~]$ hbase shell 2016-03-04 11:04:27,569 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.0.0-cdh5.5.1, rUnknown, Wed Dec 2 10:36:43 PST 2015 hbase(main):001:0> list TABLE ERROR: Can't get master address from ZooKeeper; znode data == null
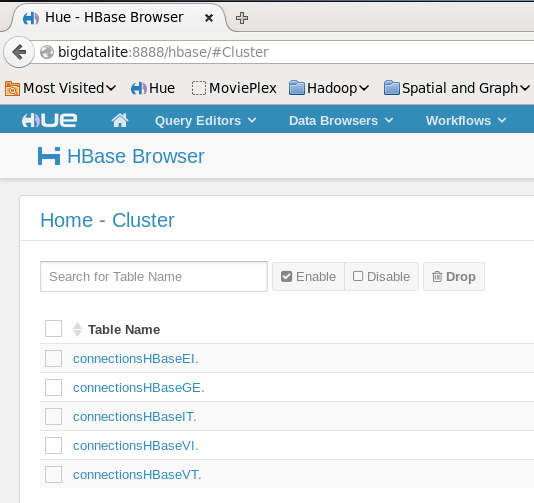
Similarly, HBase tables are not available through the Data Browsers menu of Hue (not shown).
In order to be able to use HBase, you have to disable Cloudera Manager from the Start/Stop Services desktop icon, and manage the Hadoop services manually (it is advised that you perform a system reboot after shutting down Cloudera Manager); so, your Start/Stop Services menu should look like the following image:
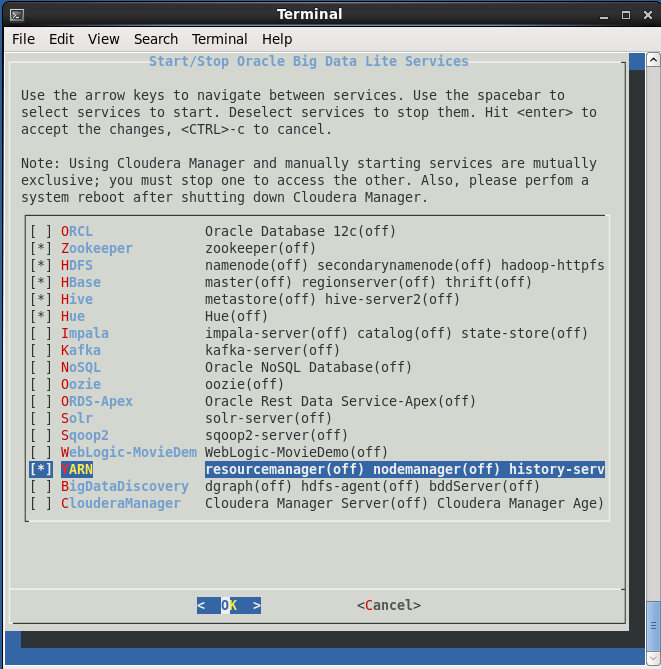
After manually starting the services, HBase works OK, both in the shell and in Hue:
hbase(main):001:0> list TABLE connectionsHBaseEI. connectionsHBaseGE. connectionsHBaseIT. connectionsHBaseVI. connectionsHBaseVT. 5 row(s) in 0.1700 seconds => ["connectionsHBaseEI.", "connectionsHBaseGE.", "connectionsHBaseIT.", "connectionsHBaseVI.", "connectionsHBaseVT."]
Bulk loading data to HBase table
For demonstration, we will use some dummy data – copy the following dummy stock data (with symbol, closing price, and current price columns), save them in your home folder in a text file stocks.txt:
XYZ 43.5 39.9 AAA 12.8 14.2 CBA 120.3 120.3 ZYX 101.2 101.4 ZZZ 28.4 32.9 BBB 30.1 30.1 QQQ 13.2 12.1 GDM 126.7 135.2
and put it in an HDFS directory data/stocks using Hue, or the following shell commands:
[oracle@bigdatalite ~]$ hdfs dfs -mkdir data [oracle@bigdatalite ~]$ hdfs dfs -mkdir data/stocks [oracle@bigdatalite ~]$ hdfs dfs -put stocks.txt data/stocks [oracle@bigdatalite ~]$ hdfs dfs -ls data/stocks Found 1 items -rw-r--r-- 1 oracle oracle 124 2016-03-04 12:11 data/stocks/stocks.txt
Now, the standard way for bulk loading into HBase tables involves two stages: first, use ImportTsv to convert the HDFS files into a storefile:
[oracle@bigdatalite ~]$ hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Closing:Price,Current:Price" -Dimporttsv.bulk.output="/user/oracle/data/stocks/storefile" Stocks /user/oracle/data/stocks/stocks.txt
after which a new HDFS directory, storefile, is created:
[oracle@bigdatalite ~]$ hdfs dfs -ls data/stocks/storefile Found 3 items drwxr-xr-x - oracle oracle 0 2016-03-04 12:19 data/stocks/storefile/Closing drwxr-xr-x - oracle oracle 0 2016-03-04 12:19 data/stocks/storefile/Current -rw-r--r-- 1 oracle oracle 0 2016-03-04 12:19 data/stocks/storefile/_SUCCESS
The second step is to use LoadIncrementalHFiles to load this just-created storefile into our HBase table Stocks.
But if we try so, the job just gets stuck, without progress or any error message:
[oracle@bigdatalite ~]$ hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /user/oracle/data/stocks/storefile Stocks [...] 2016-03-04 12:27:37,842 INFO [LoadIncrementalHFiles-1] mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://bigdatalite.localdomain:8020/user/oracle/data/stocks/storefile/Current/666e09a3a27d4d5097543c4079c5cf17 first=AAA last=ZZZ 2016-03-04 12:27:37,842 INFO [LoadIncrementalHFiles-0] mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://bigdatalite.localdomain:8020/user/oracle/data/stocks/storefile/Closing/a8567fce183b4d4886bd435f94b2c264 first=AAA last=ZZZ
What’s happening? Well, it turns out that the LoadIncrementalHFiles command tries to move the files created in the previous step by ImportTsv, but, since the owner of these files is oracle and not hbase, it cannot do it. So, we have to change the owner of these files to hbase as follows:
[oracle@bigdatalite ~]$ hdfs dfs -chown -R hbase:hbase /user/oracle/data/stocks/storefile
After which, the job runs smoothly, and the storefile subdirectories are actually empty:
oracle@bigdatalite scripts]$ hdfs dfs -ls data/stocks/storefile Found 3 items drwxr-xr-x - hbase hbase 0 2016-03-04 12:48 data/stocks/storefile/Closing drwxr-xr-x - hbase hbase 0 2016-03-04 12:48 data/stocks/storefile/Current -rw-r--r-- 1 hbase hbase 0 2016-03-04 12:48 data/stocks/storefile/_SUCCESS [oracle@bigdatalite scripts]$ hdfs dfs -ls data/stocks/storefile/Closing [oracle@bigdatalite scripts]$ hdfs dfs -ls data/stocks/storefile/Current [oracle@bigdatalite scripts]$
For convenience, we could gather all these necessary steps in a bash script:
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \ -Dimporttsv.columns="HBASE_ROW_KEY,Closing:Price,Current:Price" \ -Dimporttsv.bulk.output="/user/oracle/data/stocks/storefile" \ Stocks \ /user/oracle/data/stocks/stocks.txt hdfs dfs -chown -R hbase:hbase /user/oracle/data/stocks/storefile hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /user/oracle/data/stocks/storefile Stocks
And we can easily confirm that our HBase table Stocks is indeed created and loaded with the data:
hbase(main):001:0> list TABLE Stocks connectionsHBaseEI. connectionsHBaseGE. connectionsHBaseIT. connectionsHBaseVI. connectionsHBaseVT. 6 row(s) in 0.1580 seconds => ["Stocks", "connectionsHBaseEI.", "connectionsHBaseGE.", "connectionsHBaseIT.", "connectionsHBaseVI.", "connectionsHBaseVT."] hbase(main):002:0> scan 'Stocks' ROW COLUMN+CELL AAA column=Closing:Price, timestamp=1457113705825, value=12.8 AAA column=Current:Price, timestamp=1457113705825, value=14.2 BBB column=Closing:Price, timestamp=1457113705825, value=30.1 BBB column=Current:Price, timestamp=1457113705825, value=30.1 CBA column=Closing:Price, timestamp=1457113705825, value=120.3 CBA column=Current:Price, timestamp=1457113705825, value=120.3 GDM column=Closing:Price, timestamp=1457113705825, value=126.7 GDM column=Current:Price, timestamp=1457113705825, value=135.2 QQQ column=Closing:Price, timestamp=1457113705825, value=13.2 QQQ column=Current:Price, timestamp=1457113705825, value=12.1 XYZ column=Closing:Price, timestamp=1457113705825, value=43.5 XYZ column=Current:Price, timestamp=1457113705825, value=39.9 ZYX column=Closing:Price, timestamp=1457113705825, value=101.2 ZYX column=Current:Price, timestamp=1457113705825, value=101.4 ZZZ column=Closing:Price, timestamp=1457113705825, value=28.4 ZZZ column=Current:Price, timestamp=1457113705825, value=32.9 8 row(s) in 0.1150 seconds

- Streaming data from Raspberry Pi to Oracle NoSQL via Node-RED - February 13, 2017
- Dynamically switch Keras backend in Jupyter notebooks - January 10, 2017
- sparklyr: a test drive on YARN - November 7, 2016
[…] I need to insert data with more than 50 million lines that is in s3 in a hbase table. I am using AWS EMR to use cluster with hadoop services like hbase. I’ve already managed to put the s3 data in the hdfs and I need to pass this data to the hbase table. The mapreduce ImportTsv was not efficient to carry a large data load, so I found that I have to use bulk load. I’m using this tutorial for that: https://www.nodalpoint.com/bulk-load-data-to-hbase-in-oracle-big-data-appliance/ […]