In a previous post, we described how we performed exploratory data analysis (EDA) in real-world log files, as provided by Skroutz.gr, the leading online company in Greece for online price comparison, in the context of Athens Datathon 2015. In the present post we will have a look at the same job as performed with Oracle Big Data Discovery (v. 1.1), aiming to highlight the advantages that such a tool can offer in big data exploration.
A quick reminder of the data & the setting
We were given 30 log files from the data provider web servers, one for each day of September 2013, along with a file with some elementary anonymized demographic information of their registered users. The first 6 records of the users info and the first log file look like this, respectively:
> head(users)
id registration.date registration.type sex DOB
1: 5f183c75ae05809c7a032086d00a96dbfb2e20d3 2006-11-18 03:00:01 +0200 0
2: a403461d184f687966e81b17ccac6a13aebca1aa 2006-11-18 03:00:01 +0200 0
3: 384b411b1e0d5a85987fce29cf269f225c677f71 2006-11-18 03:00:01 +0200 0 male 1988-01-01
4: 7e5319d97b4efe14d87007681530949d883732ec 2006-11-18 03:00:01 +0200 0 male 1976-01-01
5: 6de81938fb6b49dbbe27aa67a7253cb90e622499 2006-11-18 03:00:01 +0200 0 male 1975-01-01
6: a33c5bd9e1f165367bc75c3b305ef4c030dbb7e6 2006-11-18 03:00:01 +0200 0 male 1975-01-01
> nrow(users)
[1] 15218
> head(df)
sttp UserSessionId RegisteredUserId PathURL action Time Query CategoryId
1: 22 89eca7cf382112a1b82fa0bf22c3b6c0 /search 1377982801.6669302 Ï„Ïαπεζι κουζινας με καÏεκλες
2: 10 edec809dcd22538c41ddb2afa6a80958 /products/show/13160930 1377982802.7676952 12Q420 405
3: 22 333542d43bc440fd7d865307fa3d9871 /search 1377982803.1507218 maybelline
4: 10 df15ec69b3edde03f3c832aa1bba5bed /products/show/9546086 1377982803.4333012 Hugo Boss 790
5: 10 d8b619b5a14c0f5f4968fd23321f0003 /products/show/8912067 1377982804.0093067 xbox 360 109
6: 22 d2a0bb0501379bfc39acd7727cd250e8 9a7950cf6772b0e837ac4f777964523b5a73c963 /search 1377982804.6995797 samsung galaxy s4 mini
ShopId ProductID
1:
2: de12f28477d366ee4ab82fbab866fb9fca157d5c 7c1f7d8ed7c7c0905ccd6cb5b4197280ea511b3e
3:
4: d1c8cad880ecd17793bb0b0460cb05636766cb95 f43f7147a8bf6932801f11a3663536b160235b1f
5: 5149f83f83380531b226e09c2f388bffc5087cbe 550ae3314e949c0a7e083c6b0c7c6c1a4a9d2048
6:
RefURL SKU_Id #Results
1: http://www.skroutz.gr/c/1123/dining_table.html?keyphrase=%CF%84%CF%81%CE%B1%CF%80%CE%B5%CE%B6%CE%B9+%CE%BA%CE%BF%CF%85%CE%B6%CE%B9%CE%BD%CE%B1%CF%82&order_dir=asc&page=2 3
2: http://www.skroutz.gr/s/442786/Siemens-WM12Q420GR.html?keyphrase=12Q420 442786
3: http://www.skroutz.gr/search?keyphrase=maybelline+bb 11
4: http://www.skroutz.gr/s/1932513/Hugo-Boss-0032S.html 1932513
5: http://www.skroutz.gr/c/109/gamepads.html?keyphrase=xbox+360&order_dir=asc&page=11 1475611
6:
> nrow(df)
[1] 330032
The attribute linking the two pieces of data (log files & users info) is RegisteredUserId: that is, in a log entry of a registered user, this attribute is equal to the id attribute of the respective user in the users info file (shown above). For a non-registered user, the attribute in the log is simply missing (e.g. the 5 first values in df shown above).
As we have described in detail in a previous post, during the datathon, and using typical data analysis tools such as R & Python, we uncovered a user in the provided log files, which was anomalous in at least three ways:
- He/she performed an extremely high number of actions, each and every day, for the whole month
- Although registered, he/she was not included in the registered users file
- All his/her actions were exclusively of one specific type
It is important to point out that the starting point of our discovery was the second bullet above; that is, during our sanity checks, we realized that there were actions in the logs by users which, although registered, they were not included in the provided registered users info file.
The reason I am stressing this is, I hope, obvious: if this anomalous (registered) user was indeed included in the registered users file, there is a good probability that we would had never discovered him/her! And if you consider such an outcome rather improbable, let me remind you that, out of the 13 other datathon teams, no one uncovered this anomaly, which, as it turned out, invalidated several key “findings”, as reported by all other teams.
So, just imagine about 40 people, many of which were undoubtedly brilliant and talented, after having dealt with a particular dataset for over 8 hours, being informed only during our presentation that such a “monstrous” user had been laying hidden in the data, just under their noses…
Well, to be honest, sounds like a situation I would definitely never like to find myself into…
Elementary data preparation for Oracle Big Data Discovery
My preferred way for uploading data to Big Data Discovery (BDD) is via Hive; so, after we have made the directory /user/oracle/datathon in the Hadoop file system (HDFS), we run the following Hive DDL query in order to construct an external table named weblogs:
USE default; CREATE EXTERNAL TABLE weblogs ( sttp STRING, usersessionid STRING, registereduserid STRING, pathurl STRING, action STRING, datetime STRING, query STRING, categoryid STRING, shopid STRING, productid STRING, refurl STRING, sku_id STRING, results STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' STORED AS TEXTFILE LOCATION '/user/oracle/datathon/'
Since we are not actually going to work with Hive, we don’t have to worry about the specific data types: it suffices to declare them all simply as strings; as we will see below, data types will automatically be inferred by BDD after importing (and we will also have the option to change them).
We can either copy and paste the query to the Hive query editor in Hue, or simply save it in a file init_table.sql, and run it from the command line as follows:
[oracle@bigdatalite ~]$ beeline -u jdbc:hive2:// -f ~/myscripts/init_table.sql
At this stage, we can simply upload our data files to HDFS and subsequently to BDD with just two commands in the shell; here we choose to include an additional stage of preprocessing the log files in R, in order to:
- Remove the quotes around the fields
- Change the
datetimefield from Unix timestamp to human-readable format - Change the field separator from comma to the more unambiguous pipe symbol (
|) - Save the result in a temporary file and move it to HDFS before deleting it from the local file system
We repeat that nothing from the above is strictly necessary (which is important, especially if one is in a hurry to get a quick first glimpse of the data); we choose to do so simply to “prettify” the data appearance. Also notice that our preprocessing script is just in vanilla R, i.e. it is not using the Oracle R connectors for Hadoop included in Oracle R Advanced Analytics for Hadoop (ORAAH), which is a distinct Oracle product licensed separately.
With these in mind, here is our simple preprocessing script in R, logs_to_hdfs.R (highlighting the lines performing the actions we have just described):
library(data.table)
setwd("/media/sf_C_DRIVE/datathon/weblogs")
ff <- list.files()
if (length(ff) == 0) {
message('No files present. Nothing to process...')
} else {
message(paste0(length(ff),' file(s) present. Proceeding to process and move to HDFS...'))
names.df = c('sttp','UserSessionId', 'RegisteredUserId', 'PathURL',
'action', 'datetime', 'Query', 'CategoryId', 'ShopId',
'ProductID', 'RefURL', 'SKU_Id','Results')
recs <- numeric(length(ff))
k <- 1
for (f in ff) {
message(paste0('Processing file #', k, ' - ', f))
df = fread(f, header=FALSE)
recs[k] <- nrow(df)
setnames(df,names.df)
df[,datetime := as.POSIXct(as.numeric(datetime), origin="1970-01-01", tz = 'Europe/Athens')]
file.name <- paste0('~/temp/', f)
write.table(df, file=file.name, sep='|', row.names=FALSE, quote=FALSE, col.names=FALSE)
k <- k + 1
} # end for
message(paste0('Finished processing ', sum(recs), ' records in ', length(ff), ' file(s)'))
message('Moving to HDFS & deleting temporary file(s)...')
system('hdfs dfs -put ~/temp/*.* /user/oracle/datathon/') # move processed files to HDFS
unlink('~/temp/*.*') # remove temporary files
} # end if/else
Our R script can of course be invoked from the command line, which makes it particularly useful for cron jobs, as we will discuss below. Let us now move the logs for the first three days in the /weblogs directory and then run the script:
[oracle@bigdatalite ~]$ ls /media/sf_C_DRIVE/datathon/weblogs 2013_09_01.log 2013_09_02.log 2013_09_03.log [oracle@bigdatalite ~]$ Rscript ~/myscripts/logs_to_hdfs.R 3 file(s) present. Proceeding to process and move to HDFS... Processing file #1 - 2013_09_01.log Read 330032 rows and 13 (of 13) columns from 0.079 GB file in 00:00:06 Processing file #2 - 2013_09_02.log Read 451017 rows and 13 (of 13) columns from 0.108 GB file in 00:00:04 Processing file #3 - 2013_09_03.log Read 461479 rows and 13 (of 13) columns from 0.110 GB file in 00:00:03 Finished processing 1242528 records in 3 file(s) Moving to HDFS & deleting temporary file(s)...
We are now ready to import the data to BDD, using the command line interface (CLI) with the -t flag and the name of the Hive table we want to import (weblogs):
[oracle@bigdatalite ~]$ cd /u04/Oracle/Middleware/BDD-1.1.0.13.49/dataprocessing/edp_cli [oracle@bigdatalite edp_cli]$ ./data_processing_CLI -t weblogs [...] New collection name = edp_cli_edp_e35fc7f4-66f0-40a8-9967-5d1e6a13dd59 data_processing_CLI finished with state SUCCESS
“The Visual Face of Hadoop“? Well, yes…!
This is the very first screen we get, when we click on the dataset in the BDD Studio (click to enlarge):
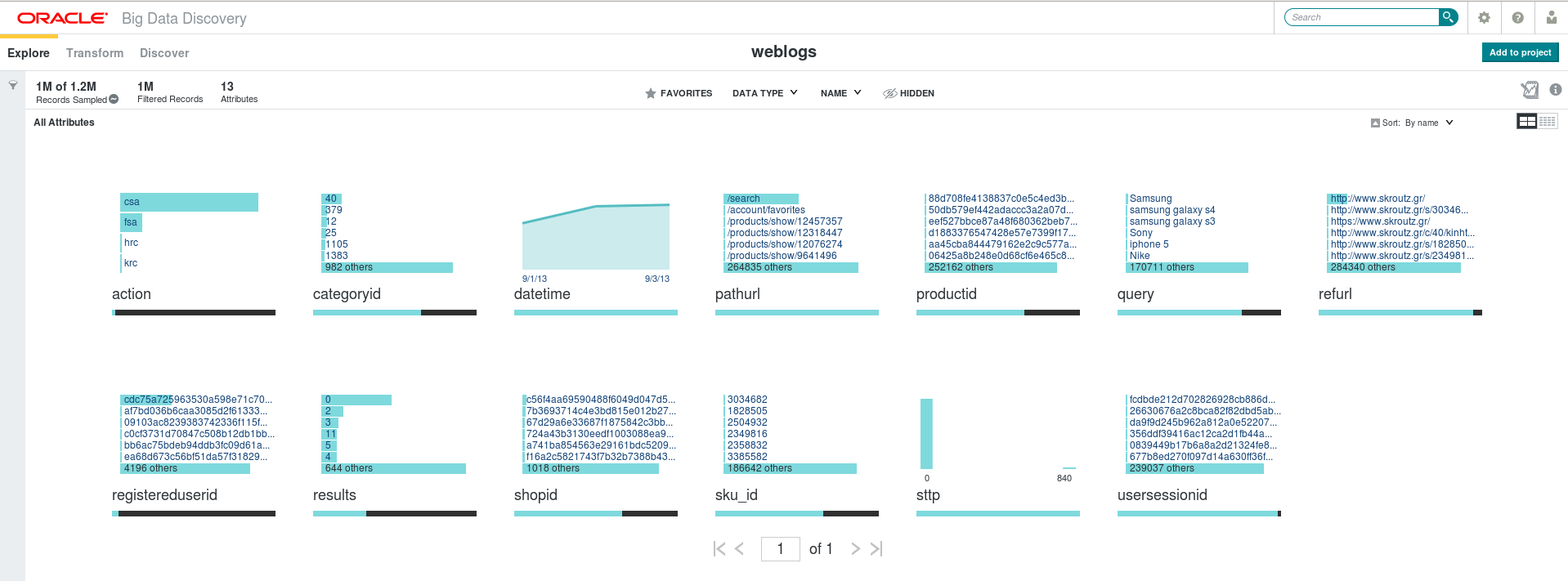
Fig. 1: The “welcome” screen in Oracle Big Data Discovery Studio. The horizontal light green bars represent counts of the respective attribute value.
Take a minute to look at the (enlarged) screenshot above; imagine that you don’t have any prior knowledge about the dataset, i.e. you don’t know anything about the possible existence of an anomalous user, you do not even look specifically for anomalies – in fact, you still do not know exactly what you are looking for, which is an absolutely legitimate status in the beginning of an exploratory data analysis project (or project phase). What would most probably catch your attention for further exploration?
datetime is roughly uniform. Most attributes display their highest counts for “other” values (i.e. for all other values not displayed in the limited space of the screen), which is rather expected; pathurl & refurl look as exceptions to this rule, but their corresponding highest-count values, upon closer inspection, look again trivial and expected (/search for pathurl, the home page of Skroutz.gr for refurl).
Practically, this leaves us with action, registereduserid, and sttp.
By now, and with the ex post facto knowledge of the analysis presented in our previous post, we can already see visually our “phantom user”, popping out of all other entries in registereduserid. But let’s suppose for the moment that we still have not noticed this; let’s say that we choose to have a closer look at the csa action, which is the one most frequently performed by the users (in fact it is not, as we will see later!): all we have to do is just click on the bar representing csa, to get the following screen (click to enlarge).
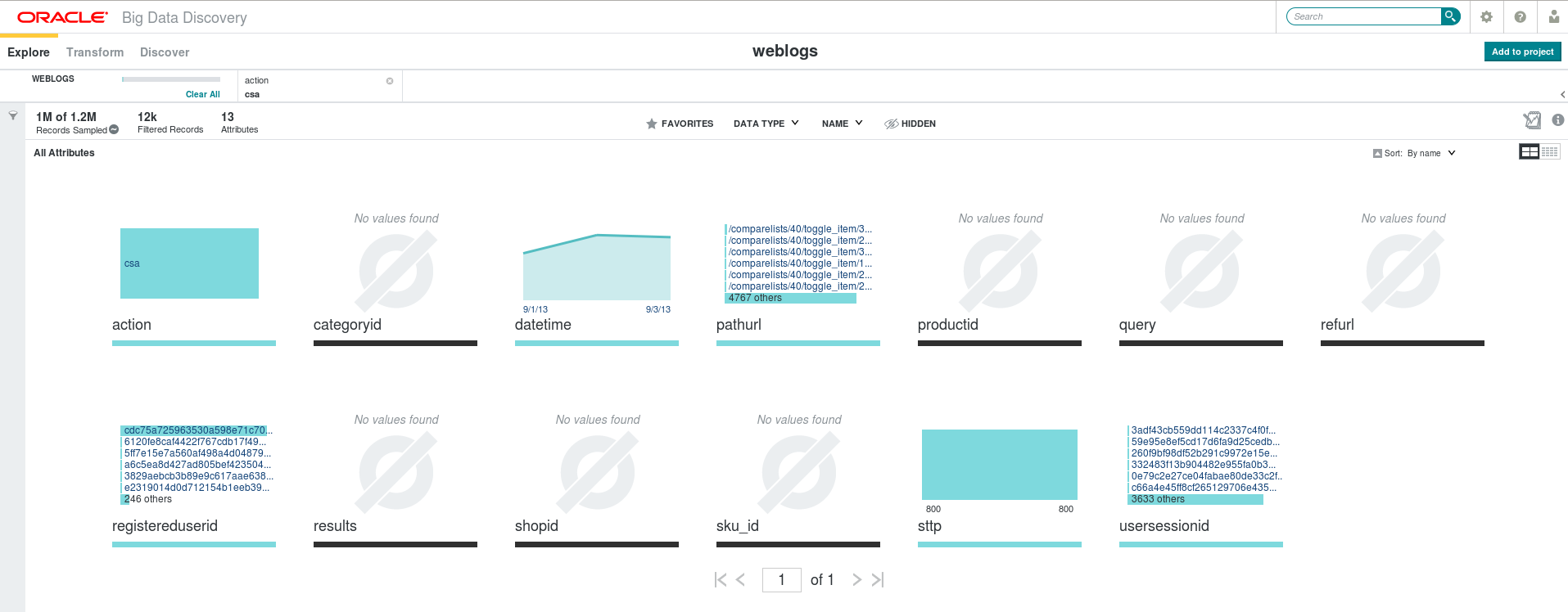
Fig. 2: “csa” only actions selected
Well, now we cannot but notice the existence of a registereduserid value with an abnormally high number of records in the logs. Clicking one more time under the respective attribute we get the following visualization (click to enlarge):
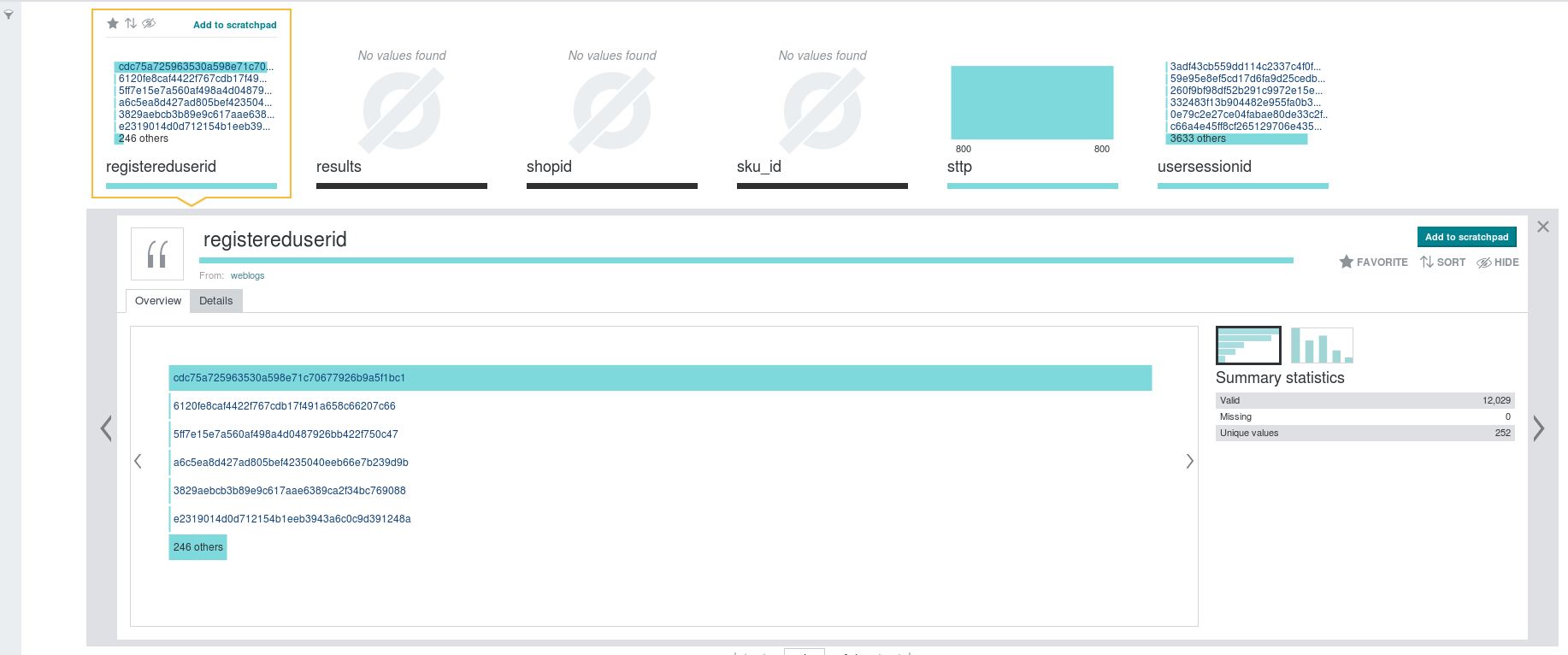
Fig. 3: Phantom user revealed after just 2 clicks
Hovering with the mouse over the first user depicted above (not shown) gives that there are about 13,900 records with this value (recall that we have imported logs from only the first 3 days); the respective counts for the second & third user are only 24 and 22.
What has actually just happened is that we revealed the phantom user with only 2 clicks…
Most importantly, notice that we have not used at all the users info file (as was the case in the previous post): here, the phantom user was revealed specifically on the grounds of his/her most anomalous trait, i.e. the extremely high number of records (actions) in the logs (which is arguably more important than the mere fact of his/her not inclusion in the registered users info file).
Having revealed our phantom user, what it takes to look at him/her more closely on isolation is just -well, you have probably guessed it by now- one click:
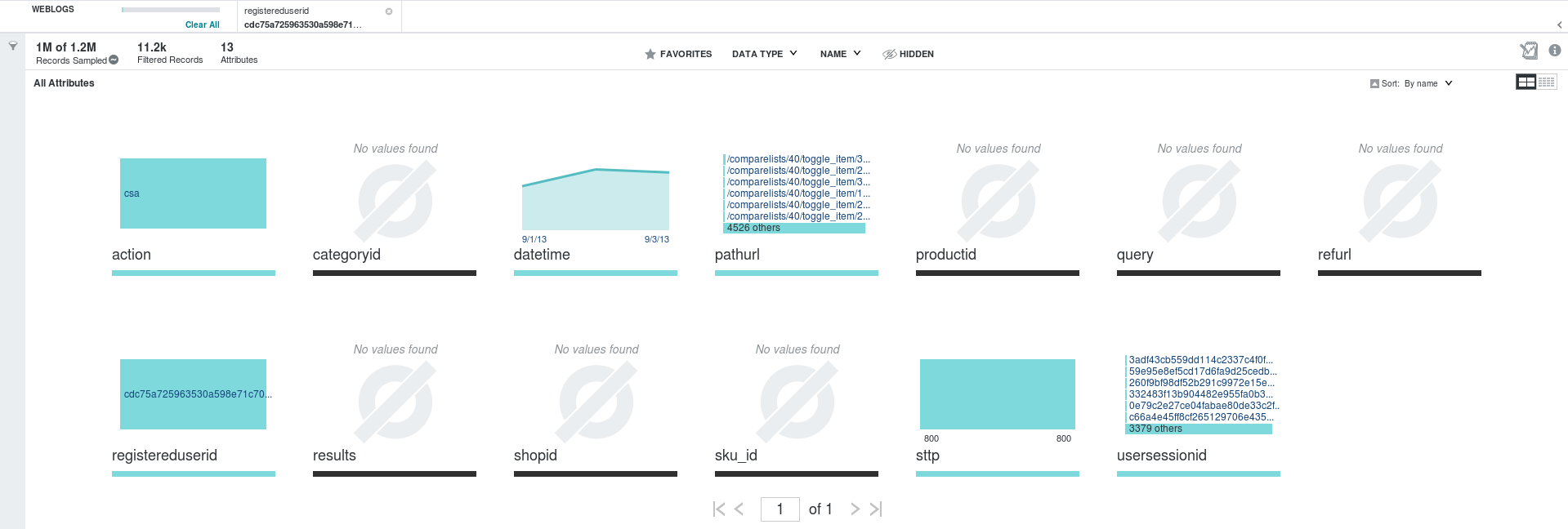
Fig. 4: Filtered records with only the phantom user included
All the additional characteristics of our phantom user’s behavior, i.e. the performance of only 800-type activities (sttp) and csa actions (“add to comparison list”) are just there, staring at us, not only without having to run specific queries, as previously (this is the easy part), but before even thinking of the respective questions!
Wondering how our data look without the phantom? Well, it takes only one click to invert the filter from inclusion to exclusion (click to enlarge):
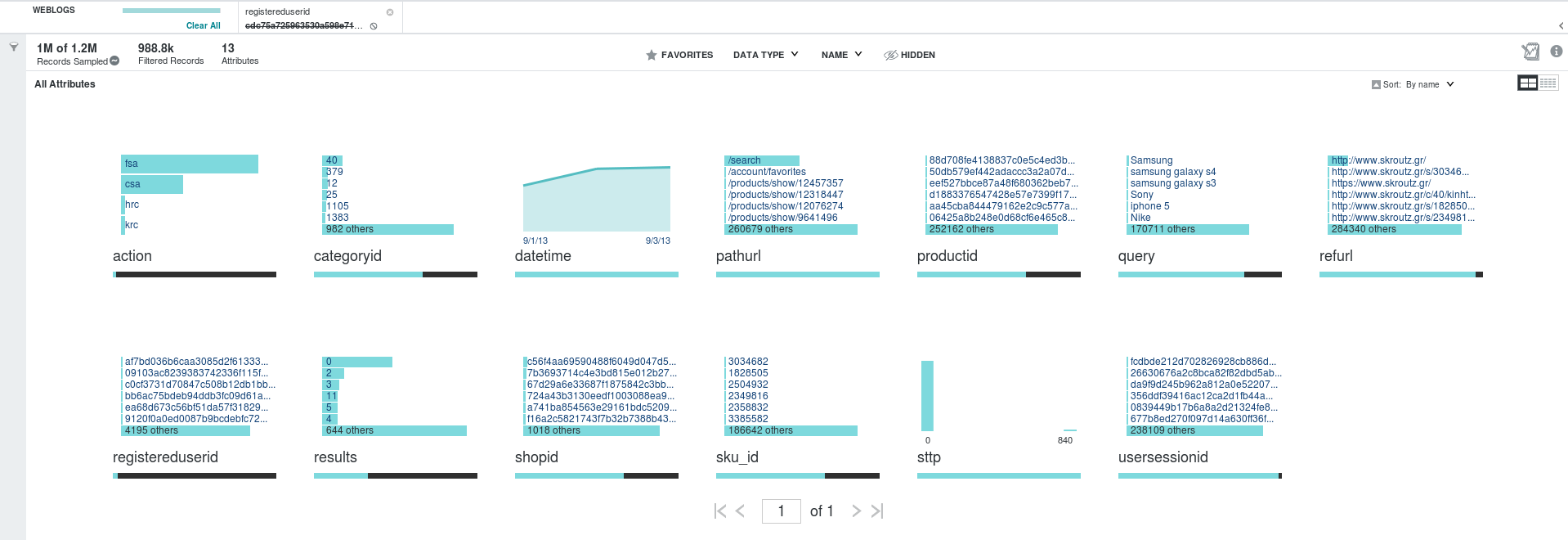
Fig. 5: Filtered records with the anomalous user excluded
Recall from Fig. 1 above (and our hint) that csa seemed to be the most frequently performed action in the data? Well, as you can see in Fig. 5, when we exclude the phantom and look only at the legitimate users, this is not the case, and the most frequently performed action actually turns out to be fsa (“add sku to favorites”).
I could go on, but I guess I have made my point clear by now…
Updating the data & using cron jobs
Working with external Hive tables means that our HDFS data stay where we have put them, and Hive is only used as a metadata store; so, if we want to import more files in an existing BDD dataset we have just to:
- Copy the required files in our /weblogs directory
- Run our logs_to_hive R script
- Update the dataset in BDD using the CLI
Let’s see an example: suppose that we want to additionally import data for two more days, 2013_09_04.log & 2013_09_05.log, in our existing BDD dataset weblogs; imagine also that, by mistake, we have forgotten in the /weblogs directory one of the files already imported in BDD, say 2013_09_01.log. Here is what happens:
[oracle@bigdatalite ~]$ ls /media/sf_C_DRIVE/datathon/weblogs 2013_09_01.log 2013_09_04.log 2013_09_05.log oracle@bigdatalite ~]$ Rscript ~/myscripts/logs_to_hdfs.R 3 file(s) present. Proceeding to process and move to HDFS... Processing file #1 - 2013_09_01.log Read 330032 rows and 13 (of 13) columns from 0.079 GB file in 00:00:06 Processing file #2 - 2013_09_04.log Read 456996 rows and 13 (of 13) columns from 0.109 GB file in 00:00:04 Processing file #3 - 2013_09_05.log Read 455699 rows and 13 (of 13) columns from 0.109 GB file in 00:00:03 Finished processing 1242727 records in 3 file(s) Moving to HDFS & deleting temporary file(s)... put: `/user/oracle/datathon/2013_09_01.log': File exists [oracle@bigdatalite ~]$ cd /u04/Oracle/Middleware/BDD-1.1.0.13.49/dataprocessing/edp_cli [oracle@bigdatalite edp_cli]$ ./data_processing_CLI --refreshData edp_cli_edp_e35fc7f4-66f0-40a8-9967-5d1e6a13dd59 [...] Refreshing existing collection: edp_cli_edp_e35fc7f4-66f0-40a8-9967-5d1e6a13dd59 Collection key for new record: refreshed_edp_cde4bbde-30b5-48ce-b749-d9df4896be35 data_processing_CLI finished with state SUCCESS
The first highlighted line in the above snippet informs us that, since file 2013_09_01.log was found to exist in HDFS, it was not moved; that’s good, as it means that we do not have to worry about importing duplicate records which would skew our data and invalidate our analysis.
The second highlighted line above includes the data set key, which must be included in the dataset refresh operation; it can be easily obtained from BDD Studio as described in detail in the BDD Data Processing Guide.
Although, as pointed out in the documentation and shown above, the data set key changes after the refresh, this happens only the first time; hence, after the initial data import and the first refresh update, we have all the necessary ingredients so as to set up a complete pipeline including a cron job for periodic updates of our weblogs dataset in BDD.
Reflections
The above visual experience, placed side by side with the investigation as it is described in our previous post, conveys a clear message:
When time-to-insight is critical, tools like Oracle Big Data Discovery are invaluable.
In our case (i.e. the datathon event), the difference between promptly and not-so-promptly revealed insights probably cost us a prize.
In real-world situations this difference could be much more costly.
Even when time is not a factor, however, it is always likely to miss a true elephant in the room, as it happened with the other datathon teams.
With Big Data Discovery at hand, it would have been straightforward for everyone to see that this statistical anomaly was actually there, and guide their analysis accordingly.
Bottom line: if there is a way that my (big) data themselves can show me which are the interesting questions to ask, well, sign me up…

- Streaming data from Raspberry Pi to Oracle NoSQL via Node-RED - February 13, 2017
- Dynamically switch Keras backend in Jupyter notebooks - January 10, 2017
- sparklyr: a test drive on YARN - November 7, 2016
[…] which we have already loaded in a Hive table named weblogs, as described in more detail in our previous post. Along the way, we will report about the necessary map-reduce (MR) jobs triggered by the commands […]