I was wondering recently if I could use Oracle R Enterprise (ORE) to query Big Data SQL tables (i.e. Oracle Database external tables based on HDFS or Hive data), since I have never seen such a combination mentioned in the relevant Oracle documentation and white papers. I am happy to announce that the answer is an unconditional yes. In this post we will provide a step-by-step demonstration, using the weblogs data we have already inserted to Hive in a previous post; our configuration is the one included in version 4.2.1 of the Oracle Big Data Lite VM.
Before enabling Big Data SQL tables, we have to download the Cloudera JDBC drivers for Hive and create a Hive connection in SQL Developer; we will not go into these details here, as they are adequately covered in a relevant Oracle blog post. Notice only that, if you use a version of SQL Developer later than 4.0.3 (we use 4.1.1 here), there is a good chance that you will not be able to use the Data Modeler in the way it is described in that Oracle blog post, due to what is probably a bug in later versions of SQL Developer (see the issue I have raised in the relevant Oracle forum).
Creating an external Big Data SQL-enabled table
After we have connected to Hive in SQL Developer, using an existing Hive table in Big Data SQL is actually as simple and straightforward as a right-click on the respective table (in our case weblogs), as shown in the figure below:
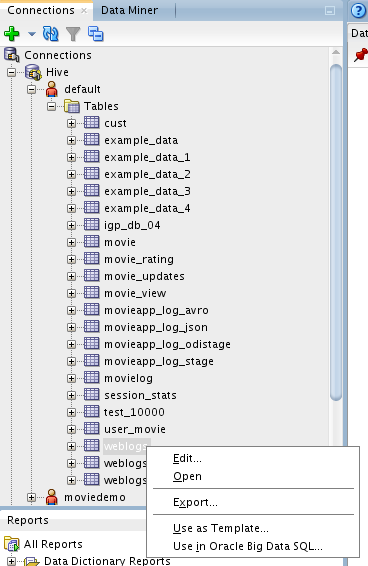
Selecting “Use in Oracle Big Data SQL…” in the menu shown above, and after answering a pop-up message for choosing the target Oracle database (we choose the existing moviedemo database for simplicity), we get to the “Create Table” screen:
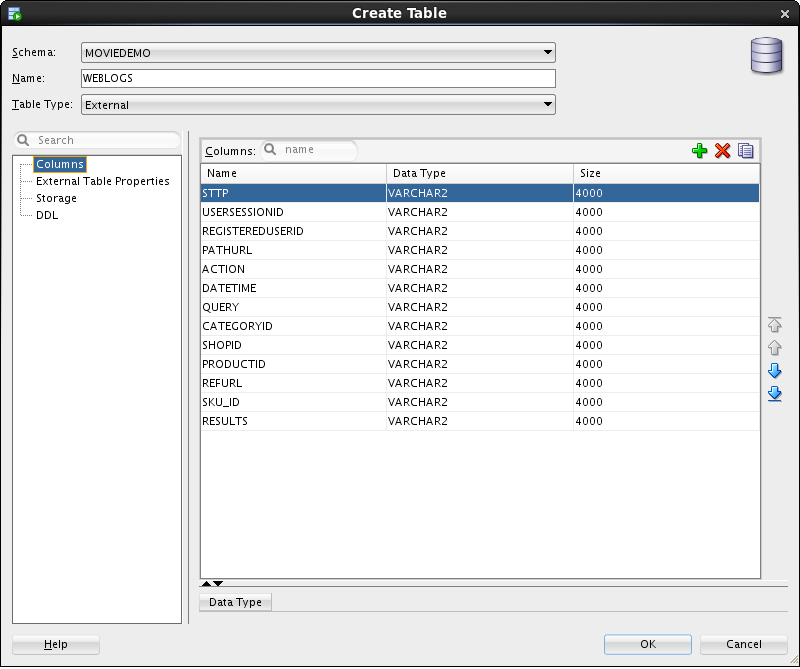
If necessary, we can alter data types and other table properties here; let’s change the DATETIME column to type TIMESTAMP. We need also to set the default directory in the “External Table Properties” tab (we choose DEFAULT_DIR here). After these changes, we can inspect the DDL statement from the corresponding tab before creating the table:
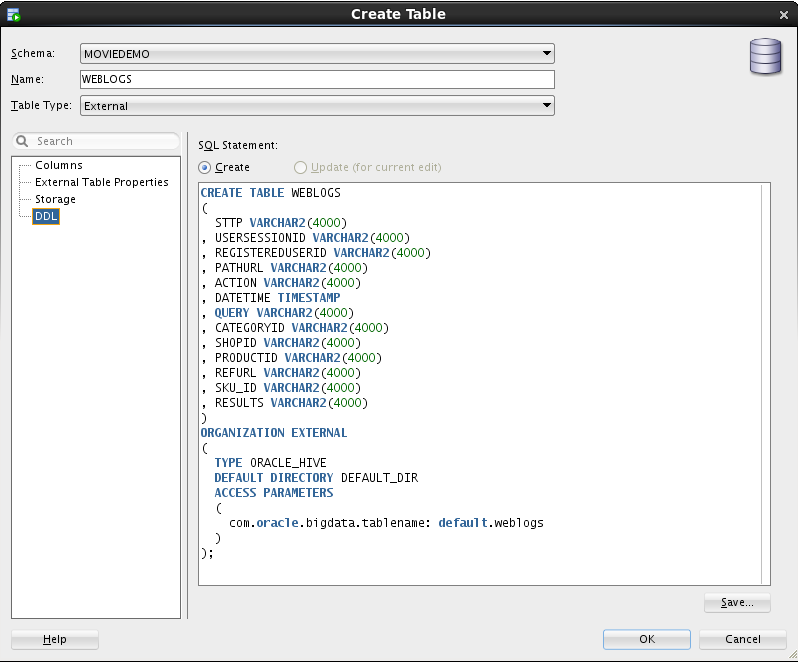 When we are satisfied with the table definition, pressing OK will actually create the (external) table in the database we have already defined (moviedemo in our case).
When we are satisfied with the table definition, pressing OK will actually create the (external) table in the database we have already defined (moviedemo in our case).
Adding the user information table in the database
Let us remind here that the weblogs data come from a use case which we have described in a previous post; to present an equivalent in-database analysis using ORE, we also create a regular (i.e. non-external) database table with the provided user information. Here is a simple ORE script for creating the table USER_INFO from the existing CSV file; notice that we don’t need to use a single SQL statement – all the processing is done in ORE with R statements:
library(ORE)
library(data.table)
setwd("/media/sf_C_DRIVE/datathon/")
users <- fread('user_info.csv', header=FALSE)
names.users <- c('id', 'registration_date', 'registration_type', 'sex', 'dob')
setnames(users, names.users)
ore.connect(user="moviedemo", sid="orcl", host="localhost", password="welcome1",
port=1521, all=FALSE)
# manipulate column types:
users[, dob:=as.Date(dob, format="%Y-%m-%d")]
users[, dob := year(dob)]
users[, registration_date := strtrim(registration_date,19)]
users[, registration_date := as.POSIXct(registration_date, format="%Y-%m-%d %H:%M:%S", tz = 'Europe/Athens')]
###
ore.create(users, table="USER_INFO") # create the table
ore.disconnect()
Let us stress here that the case we have created corresponds perfectly to a real-world situation, where the user information would lie in a database table and the weblogs would be collected and stored in Hadoop.
Querying the external table with Oracle R Enterprise
Let’s connect to the database using ORE, attaching only the two tables we have just defined:
> library(ORE)
Loading required package: OREembed
Loading required package: OREgraphics
Loading required package: OREeda
Loading required package: OREmodels
Loading required package: OREdm
Loading required package: lattice
Loading required package: OREpredict
Loading required package: ORExml
> ore.connect(user="moviedemo", sid="orcl", host="localhost", password="welcome1", port=1521, all=FALSE)
Loading required package: ROracle
Loading required package: DBI
> ore.sync(table=c("USER_INFO", "WEBLOGS")) # the second table is EXTERNAL (Big Data SQL)
> ore.ls()
[1] "USER_INFO" "WEBLOGS"
> ore.attach()
Recall from our previous post on Hive connections with ORAAH that R commands such as nrow() and dim() trigger map-reduce jobs; this is not the case here with our Big Data SQL-enabled external table:
> df <- WEBLOGS > class(df) [1] "ore.frame" attr(,"package") [1] "OREbase" > nrow(df) # No MR job triggered [1] 13108692
Let us now use ORE with the Big Data SQL-enabled table we have created above in order to replicate a part of our analysis in a previous post; we remind the reader that the crucial step in our analysis back then was the question how many users appear registered in WEBLOGS while they are not included in the USER_INFO table?
For the reader’s convenience, here is the equivalent vanilla R snippet from our previous post (using the data.table package):
> df.registered <- df[RegisteredUserId != ''] # keep only log actions by registered users > anom.id <- df.registered[!(RegisteredUserId %in% users[,id]), RegisteredUserId ] > unique(anom.id) [1] "cdc75a725963530a598e71c70677926b9a5f1bc1"
Before presenting the ORE approach, let us stress that a command similar to the first one above (i.e. select all weblog records with an empty RegisteredUserId) will not do the job here: when we create Oracle Database tables from text files, by default the empty strings are converted to NULL values in the database; hence, we need to modify the selection using the R command is.na(), as shown below (highlighted line):
> library(magrittr) > users <- USER_INFO > df.reg <- df[!is.na(df$REGISTEREDUSERID),] # keep only log actions by registered users > anom.id <- df.reg[!(df.reg$REGISTEREDUSERID %in% users[,'id']),'REGISTEREDUSERID' ] > ff <- unique(anom.id) %>% as.character %>% ore.pull > ff [1] "cdc75a725963530a598e71c70677926b9a5f1bc1"
What has actually just happened in the above ORE snippet is that, in a single line of code, we have collected our anomalous user cases anom.id combining data from:
- an ore.frame,
df.reg, which is based on an external Big Data SQL-enabled table, with the actual data laying in the Hadoop cluster and - another ore.frame,
users, which comes from a regular Oracle Database table.
Conclusion
We have demonstrated that, once an external Big Data SQL-enabled table has been created in the database, it can be queried and manipulated in Oracle R Enterprise as a regular database table; hence, the ORE user can work with data residing in the Hadoop cluster as if they were in the database, in a completely transparent manner and without using additional software components.
> ore.disconnect() > sessionInfo() Oracle Distribution of R version 3.1.1 (--) Platform: x86_64-unknown-linux-gnu (64-bit) locale: [1] C attached base packages: [1] stats graphics grDevices utils datasets methods base other attached packages: [1] magrittr_1.5 ROracle_1.1-12 DBI_0.2-7 ORE_1.4.1 ORExml_1.4.1 OREpredict_1.4.1 [7] OREdm_1.4.1 lattice_0.20-29 OREmodels_1.4.1 OREeda_1.4.1 OREgraphics_1.4.1 OREstats_1.4.1 [13] MASS_7.3-33 OREembed_1.4.1 OREbase_1.4.1 loaded via a namespace (and not attached): [1] Matrix_1.1-4 OREcommon_1.4.1 arules_1.1-3 grid_3.1.1 png_0.1-7 tools_3.1.1

- Streaming data from Raspberry Pi to Oracle NoSQL via Node-RED - February 13, 2017
- Dynamically switch Keras backend in Jupyter notebooks - January 10, 2017
- sparklyr: a test drive on YARN - November 7, 2016
Nice post, This is true SQL is a data handle language. This post is very informative and helpful for create query in the big data SQL table. SQL Data Recovery